There is only one thing stronger than all the armies of the world: and that is an idea whose time has come.
The Story Behind Internet Object
In 2017, I shipped a "simple" REST API. Within weeks, I was watching a 2KB employee list balloon to 8KB because JSON repeated every key in every record. Validation logic sprawled across six layers: server endpoints, web client, mobile apps inbound and outbound. Each team wrote the same rules differently. Bugs leaked through. Bandwidth bills climbed.
I'd noticed the problem before, but that particular day it wouldn't let go.
One question haunted me: What if we sent only the values and let a shared schema handle meaning, validation, and safety?
That spark became Internet Object: a compact, human-readable, schema-first format built for the modern web.
Good design adds value faster than it adds cost.
Data vs metadata, clearly split
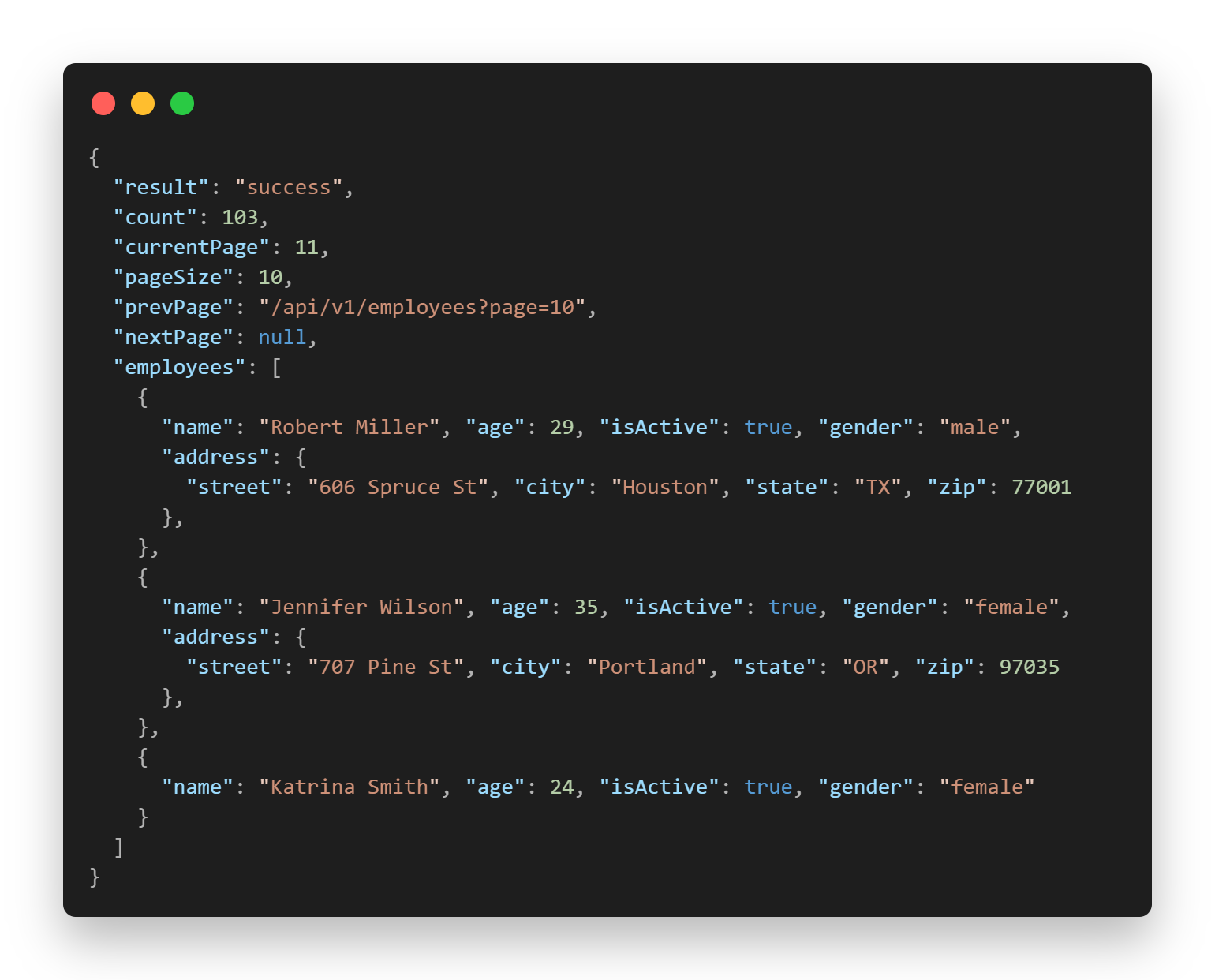
As I dug deeper into JSON's limitations, another anti-pattern emerged: data and metadata living side by side. Pagination details, result counts, and status codes tangled with actual records in the same object. Every consumer had to parse through noise to find the signal.
At scale, that blur became expensive, forcing custom DTO logic, defensive validation, and brittle contracts across teams.
A clean format needed separation by design: headers in one place, payload in another.
The quest for a better web format
Identifying the problems was the easy part. Finding a solution that didn't just swap one set of trade-offs for another, that was harder.
The blur costs clarity, bytes, and time
When metadata (result, count, page info) lives beside records, every consumer has to reconcile it in DTOs, add guardrails, and bolt on pagination/state handling in application code. That adds validation effort and cost, tighter coupling, and higher error rates: an anti-pattern versus a clean envelope/payload split.
What the web needs in a text format
I studied JSON, GraphQL, XML, YAML, CSV and even protocols like MIME and SOAP, looking for patterns. Each had insights, but none solved the full picture. What emerged was a clear set of must-haves:
- Human-readable and compact (lower payload and parse costs)
- Contract-first schema and validation (clear DTOs, strong guarantees)
- Envelope/Payload separation (headers vs data; separation of concerns)
- Streaming with backpressure (better latency and throughput)
- Helpful comments (self-documenting contracts)
- Reusability via variables/references (DRY, indirection for secrets)
- Rich canonical types (BigInt, precise decimals, temporal, NaN/Infinity)
- Platform-agnostic across storage, queues, and wire
Perfection is achieved not when there is nothing more to add, but when there is nothing left to take away.
From idea to Internet Object
With those requirements clear, I needed a name that captured the vision. "Internet Object" kept surfacing: a data object purpose-built for the web. It clicked.
No existing format checked every box, so I built one: a simple, schema-first, text format for clean, efficient data exchange.
From concept to reality
The Internet Object became my nights and weekends. I iterated, tested prototypes with developers and architects, gathered feedback, and refined the design. Work paused in 2020 to 2021, then resumed in late 2022.
After years of iteration, I'm finally happy with what we have: compact, human-readable, streaming-friendly, with variables, comments, external/embedded schemas, and a clean split between metadata and data. Most importantly, it's AI-friendly: lower cost through fewer tokens, better contracts through integrated schemas.
The GenAI advantage, a free by-product
I didn't design Internet Object for the GenAI era, that came later. But the architecture choices (compact values, shared schemas, envelope/payload split) turned out to be perfect timing.
In production GenAI workflows, token count is the primary cost driver. A 50% smaller payload can cut inference bills in half. And when models have clear schema contracts instead of ad-hoc JSON, they generate more predictable, debuggable outputs.
It's a double win: lower operational cost, higher reliability. Both free by-products of solving the original web data problem.
What it looks like
Below, you'll see two quick snapshots: a schema (external) and a REST API response mirroring the earlier JSON example but clearer and smaller.
Internet Object schema
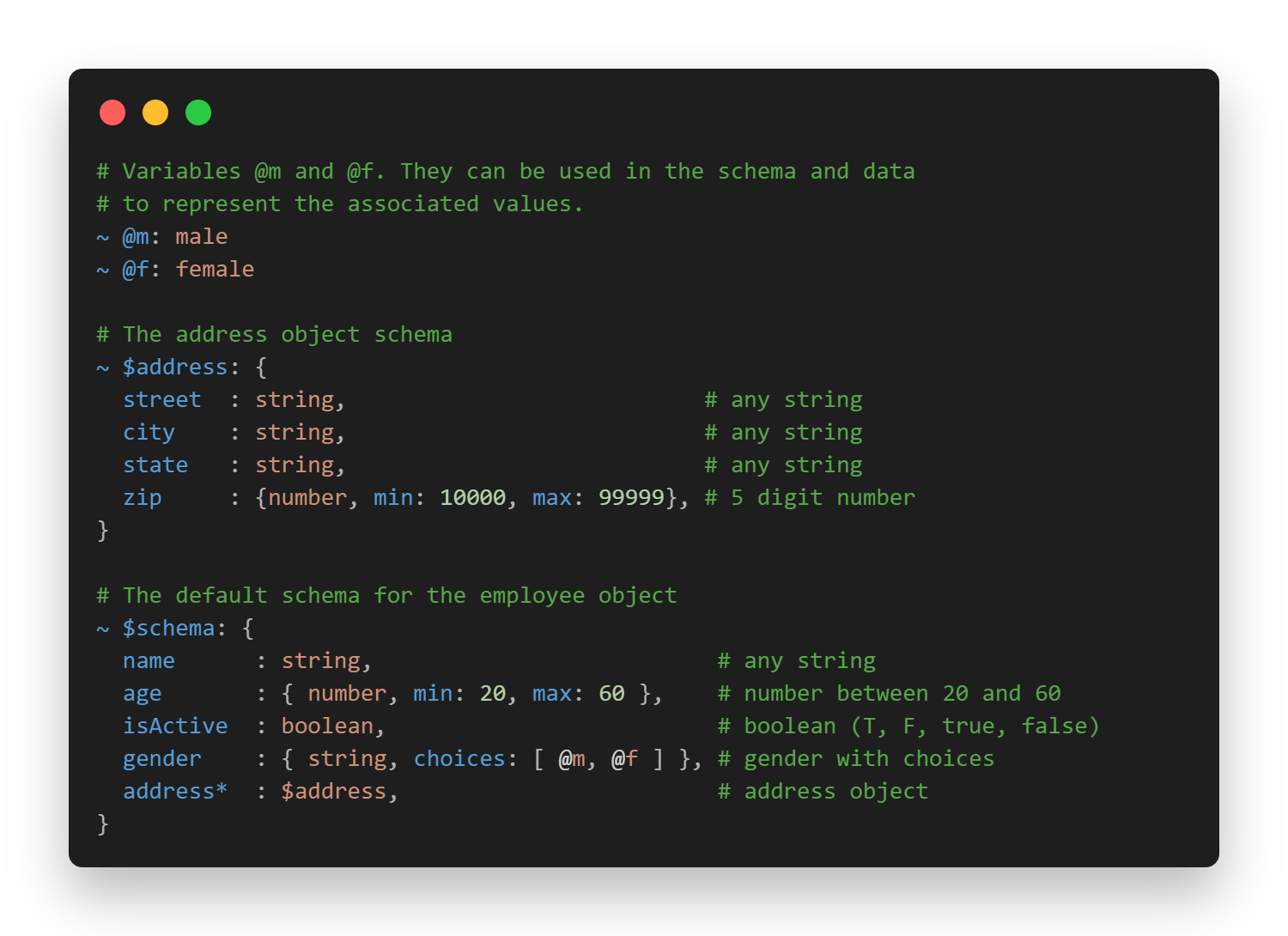
The schema defines two pieces: an address object and a default employee object, plus two gender variables.
Schema at a glance
- $address: street, city, state, zip (5-digit)
- $schema (employee): name, age (20 to 60), isActive (boolean), gender (@m/@f), optional address
It's readable, validated, and minimal: ready for both humans and machines.
A REST response in Internet Object
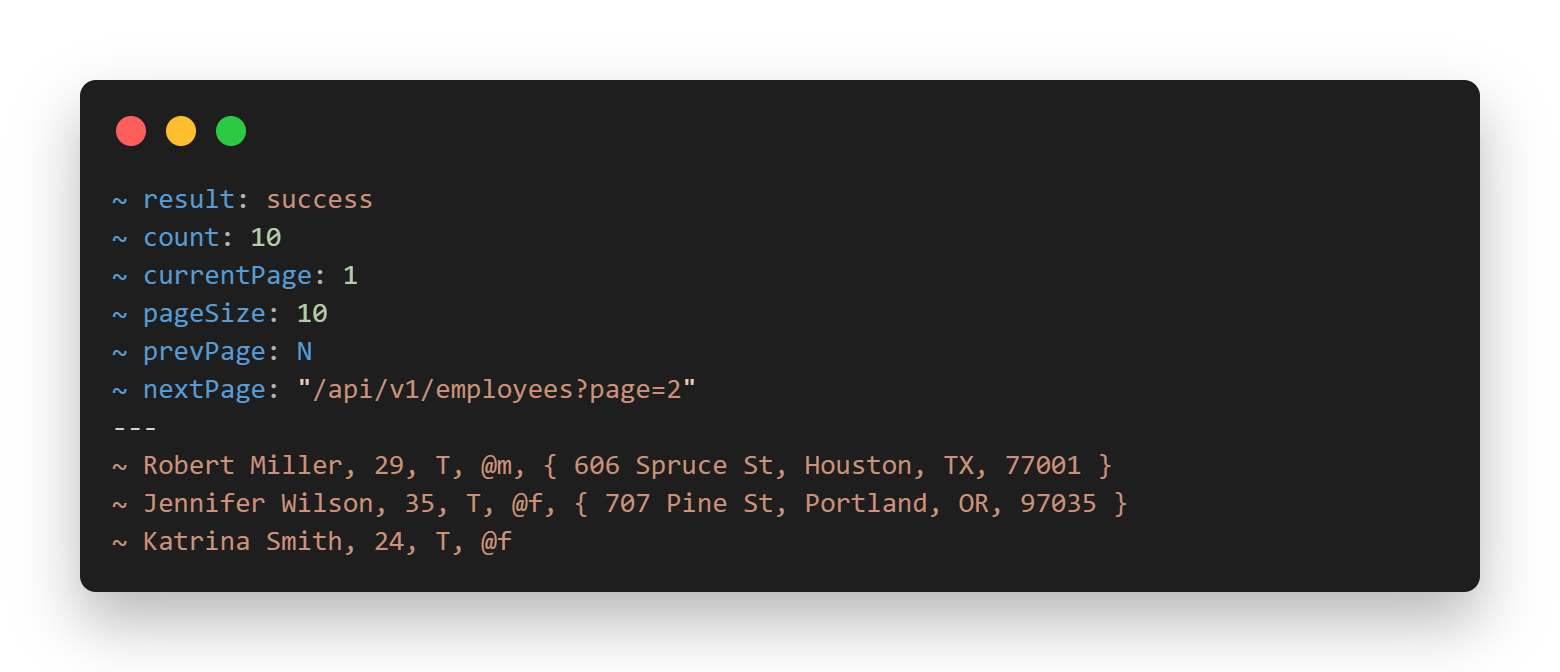
Let's see the format in action: the same employee API from page 1, but reimagined.
Headers (result, count, pagination) live in the envelope. Employee records live in the payload, clean, validated by schema, and half the size. Metadata where it belongs, data where it belongs.
Join the movement
You've seen the problem, the quest, and the solution. Internet Object is live: parsers are shipping, the playground is running, and real teams are testing it in production.
This is a small step with a big payoff: simpler payloads, clearer intent, and fewer bytes on the wire. But it needs your help to reach its potential.
Read the specs: docs.internetobject.org
Ways to help:
- Build parsers and tools
- Review and file issues
- Share feedback and use-cases
As William Gibson said: "The future is already here, it's just not very evenly distributed." Let's ship it.
(signed) Mohamed Aamir Maniar at linkedin.com/in/aamironline